MOTOSHARE 🚗🏍️
Rent Bikes & Cars Directly from Owners
Motoshare connects vehicle owners with people who need bikes and cars on rent. Owners earn from idle vehicles, and renters get flexible ride options.
Visit Motoshare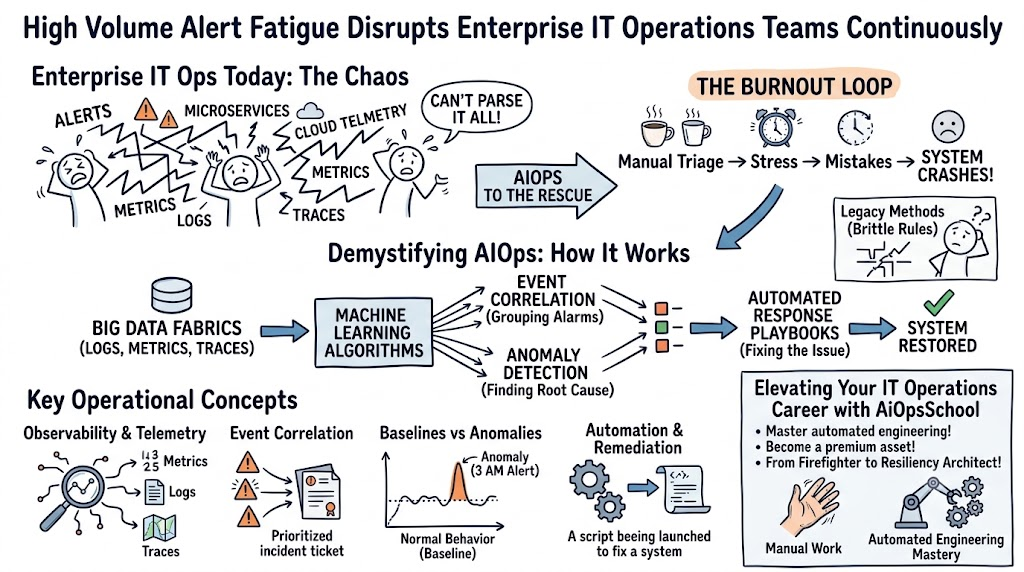
The enterprise IT landscape is under siege from its own complexity. Cloud-native architectures, microservices, and hybrid infrastructures generate an unprecedented deluge of operational data every single second. For IT engineering and operations teams, this data explosion has turned daily work into a continuous exercise in firefighting, leading to massive alert fatigue and extended outages.
Consider a typical scenario: a single microservice failure triggers a cascading avalanche of alerts across different monitoring systems. The database team sees latency spikes; the network team sees a surge in retransmissions; the application team sees HTTP 500 errors. Each system screams for attention, burying engineers under hundreds of notifications within minutes. This overwhelming noise hides the needle in a haystack of data, extending the time it takes to find and fix the problem.
Traditional, manual approaches to infrastructure management can no longer keep pace with this level of scale and velocity. Human operators cannot manually analyze gigabytes of metrics, logs, and traces in real time to isolate a failure while a critical digital platform is actively losing revenue. This operational bottleneck is precisely why modern enterprises are rapidly adopting Artificial Intelligence for IT Operations. To bridge this acute talent gap, comprehensive AIOps Training has become an absolute necessity for technology professionals looking to survive and thrive in today’s automated landscape. For those ready to lead this shift, AiOpsSchool provides the structured pathway needed to master these complex systems and transition from reactive troubleshooting to proactive engineering.
Demystifying the Intelligence Shift: What Is AIOps?
To understand how we solve these modern infrastructure problems, we must first address a fundamental question: What is AIOps? Stripped of marketing jargon, the term stands for Artificial Intelligence for IT Operations. It represents the marriage of big data, machine learning, and automation to enhance and accelerate primary IT operations processes.
Instead of relying on rigid, human-configured thresholds—such as triggering an alert only when CPU utilization crosses an arbitrary 85% mark—this approach uses data science to understand the dynamic behavior of systems. It ingests massive streams of historical and real-time data from every corner of the infrastructure, learns what constitutes “normal” operating behavior, and automatically detects deviations that point to emerging problems.
In practice, it acts as an intelligent assistant for operations teams. It continuously collects telemetry, correlates related events together into a single incident, highlights the underlying root cause, and can even trigger automated scripts to fix the issue before users ever notice a slowdown. It gives engineers the analytical firepower required to manage environments that have grown far too large for human sight alone.
Key Operational Concepts You Must Know
Before exploring specific platforms or writing machine learning models, any engineer entering this space must master the foundational concepts that govern AIOps in IT operations. These building blocks form the vocabulary of modern, intelligent infrastructure management.
Observability and Telemetry
Observability allows you to understand why a system is broken by examining its external outputs. These outputs are known collectively as telemetry, commonly categorized into the three pillars of logs, metrics, and traces. Metrics provide numeric values measured over intervals of time, such as memory usage or error rates. Logs offer structured or unstructured text records generated by applications when specific events occur. Traces map the entire end-to-end journey of a single request as it travels through a web of distributed microservices.
Event Correlation
In a large enterprise, a single infrastructure issue can trigger thousands of individual events and alerts across different layers of the technology stack. Event correlation is the process of using algorithmic models to group these related alerts together into a single, cohesive incident context. This prevents engineers from being bombarded by repetitive alerts and immediately establishes a timeline of how a failure unfolded.
Baselines versus Anomalies
Static thresholds are inherently flawed because enterprise workloads change constantly. A retail website might experience a traffic spike at 8:00 PM on a Sunday, which is perfectly normal, while that same spike at 4:00 AM on a Tuesday indicates a major anomaly. Advanced platforms establish dynamic baselines by analyzing historical cyclical patterns. An anomaly is any deviation from these mathematically calculated ranges of expected behavior, allowing systems to flag subtle irregularities long before they cross traditional limits.
Automation and Remediation
The ultimate goal of intelligent operations is to close the loop between detection and resolution. Automation and remediation involve linking the insight derived from machine learning directly to execution frameworks. Once a problem is identified with high statistical confidence, the platform can automatically run a specific playbook—such as restarting a hung container or clearing a full disk cache—resolving the incident without human intervention.
A Practical Guide to AIOps for Beginners
Transitioning into this automated world can feel overwhelming, but there has never been a more critical time to start. Exploring AIOps for beginners reveals that this field is the next logical evolution of systems engineering. If you are wondering why you should pivot your learning toward this space right now, consider these three defining factors:
- The Demise of Manual Triage: The complexity of modern software delivery means that old-school operations methodologies are becoming obsolete. Organizations are actively phasing out massive “War Rooms” where engineers sit on a phone call trying to guess which component is failing. Learning these automated patterns ensures your skills remain highly relevant to modern enterprise hiring needs.
- Massive Industry Talent Scarcity: Companies face a severe shortage of engineers who actually understand how to configure, maintain, and interpret data science outputs within an operational framework. Gaining this expertise early positions you as a premium asset in the global job market.
- A Shift from Firefighter to Architect: By automating the tedious, repetitive tasks of alert clearing and basic troubleshooting, engineers can free themselves from stressful on-call rotations. This allows you to spend your working hours designing resilient architecture, improving performance, and focusing on high-value engineering challenges rather than managing constant daily crises.
Intersecting Disciplines: AIOps vs DevOps vs MLOps
As technology paradigms evolve, acronyms frequently overlap, causing confusion across engineering teams. To build an effective career roadmap, it is essential to distinguish between these three prominent methodologies. While they all leverage automation, their focus areas, workflows, and objectives target completely different phases of the software and data lifecycles.
To understand their differences, we must look at AIOps vs DevOps as well as AIOps vs MLOps. DevOps focuses on bridging the gap between software development and IT operations to accelerate the release cycle while maintaining code quality. MLOps applies those same automated engineering principles specifically to the lifecycle of machine learning models, ensuring they can be reliably trained, deployed, and monitored in production. In contrast, intelligent operations focuses entirely on using data science insights to optimize, secure, and stabilize runtime systems, regardless of how those systems were built or deployed.
| Concept | Primary Focus | Core Question It Answers |
| DevOps | Continuous integration, software delivery speed, and cross-team collaboration. | “How can we build, test, and deploy software changes to our production environments faster and more reliably?” |
| MLOps | Machine learning model lifecycle management, versioning, and feature stores. | “How do we transition a data scientist’s prototype model into a stable, scalable production pipeline?” |
| AIOps | Automated real-time runtime stability, intelligent observability, and noise reduction. | “How can we use data science to automatically detect, analyze, and resolve anomalies in production systems?” |
Platform Implementation vs. Culture — What’s the Real Difference?
A common and costly mistake organizations make when embracing modern automation is treating it purely as a software procurement task. Executives often assume that signing an enterprise contract for a sophisticated monitoring platform immediately solves their operational woes. In reality, successful adoption requires a careful balance between platform implementation and a comprehensive cultural evolution.
When embarking on AIOps Training, engineers learn that buying and configuring a tool is only twenty percent of the battle. The remaining eighty percent centers on building the operational habits, updated processes, and organizational trust needed to act on automated insights. Without a deep cultural shift, even the most expensive software platforms simply become glorified, high-cost alerting dashboards that engineers eventually mute or ignore. Shifting an organization’s mindset requires moving away from defensive, siloed blame-shifting toward an open, shared data landscape. Teams must learn to trust algorithmic logic to aggregate alerts across multiple legacy domains, which is vital for long-term AIOps in IT operations success.
| Operational Element | Platform Implementation Only | Cultural and Process Evolution |
| Primary Focus | Licensing software, connecting APIs, configuring agents, and creating visual executive dashboards. | Breaking down team silos, redesigning response playbooks, and training staff to interpret data insights. |
| Handling Alerts | Consolidating thousands of infrastructure notifications into a centralized software console. | Establishing clear team ownership over specific metrics and defining exact boundaries for auto-remediation. |
| Trusting Automation | Writing basic rules or enabling default machine learning algorithms without deep system tuning. | Gradually building engineering confidence through dark launches, dry runs, and collaborative post-mortems. |
| Team Structure | Traditional siloed engineering teams looking at a new shared software screen. | Integrated platform engineering mindsets where cross-team data sharing and transparency are mandatory. |
| Long-Term Value | Minimal return on investment; teams suffer from the same issues because their internal habits remain unchanged. | Exponential efficiency gains; continuous reduction in incident resolution times and drastically lower operational stress. |
Core AIOps Use Cases
The practical application of machine learning within enterprise infrastructures manifests across several primary scenarios. These AIOps use cases demonstrate how data-driven automation moves teams away from reactive firefighting and toward highly optimized, self-healing environments.
- Dynamic Anomaly Detection: Rather than relying on simple thresholds that trigger alerts during harmless spikes, machine learning algorithms continuously evaluate real-time data streams against historical patterns to identify genuine operational deviations.
- Intelligent Event Correlation: Systems automatically ingest, normalize, and group thousands of independent alerts from separate monitoring tools into a single, cohesive incident ticket, filtering out distracting background noise.
- AIOps Root Cause Analysis: When a distributed application breaks, advanced tools leverage AIOps root cause analysis to instantly analyze system dependencies, topology changes, and error logs, pinpointing the specific component that initiated the failure.
- Predictive Capacity Planning: Instead of looking backward at historical resource consumption, predictive analytics evaluate usage trends over time to forecast future compute, storage, and cloud infrastructure requirements.
- Automated Incident Remediation: By connecting machine learning intelligence to automated execution frameworks, systems can resolve common, well-understood infrastructure problems autonomously without human intervention.
- Pervasive AIOps in IT Operations: Integrating these intelligent insights into everyday IT service management workflows fundamentally reshapes how support tickets are routed, categorized, and prioritized across enterprise systems to maximize AIOps in IT operations efficiency.
Real-World Use Cases of Modern Operations
To fully appreciate the impact of these technologies, let us look at how they solve concrete infrastructure challenges across different commercial industries. These examples show AIOps use cases operating at scale within modern distributed systems.
An enterprise e-commerce platform experienced a sudden checkout latency spike during a major holiday sales event. By leveraging intelligent systems, the platform automatically correlated a surge in database lock contentions with an optimized microservice version deployed just ten minutes prior, executing an automatic rollback that restored normal processing within seconds.
A global digital banking institution deployed an automated security and analytics layer to defend its core transactional services. The system successfully flagged a subtle, distributed data exfiltration attempt by identifying unusual cross-region database query volumes that fell well outside normal baseline operating habits, blocking the malicious traffic before any data compromise could occur.
A multinational SaaS provider utilized predictive analytics to manage its fluctuating multi-cloud infrastructure expenses. The platform analyzed historical utilization trends alongside incoming user subscription metrics to execute forward-looking capacity adjustments, reducing unnecessary cloud waste by automatically downscaling underutilized compute clusters before low-traffic periods. This ongoing balance optimization demonstrates the immense value of AIOps in IT operations.
AIOps Tools You Should Know
Navigating the modern ecosystem requires familiarity with the major software suites and frameworks that power intelligent automation. When engineers look for a comprehensive AIOps tools list, they find solutions distributed across four primary industry categories.
- Monitoring and Observability Platforms: These enterprise solutions excel at ingesting massive quantities of live telemetry and applying native machine learning algorithms to detect anomalies. Industry leaders include Dynatrace, Datadog, New Relic, and ScienceLogic, all prominent fixtures in the AIOps Tools market.
- Event Correlation and ITSM Tools: These platforms focus on consolidating alerts, mapping IT topologies, reducing operational noise, and orchestrating incident workflows. Prominent examples include PagerDuty, BigPanda, Moogsoft, and ServiceNow.
- Open-Source and Big Data Stacks: For organizations building custom telemetry architectures, these tools provide the storage and processing frameworks required to run custom machine learning models. The Elastic Stack (ELK), Prometheus combined with Grafana, and Apache Kafka form the baseline of many setups.
- Cloud-Native Automated Services: The major hyperscale cloud infrastructure providers offer built-in machine learning capabilities tailored specifically to their own platforms. These include Amazon DevOps Guru, Google Cloud Architecture Insights, and Microsoft Azure Advisor.
Understanding how to integrate, maintain, and extract value from these diverse platforms is a core competency for modern engineers. Exploring an introductory AIOps Tutorial serves as an excellent, natural next step to learn how these platforms process live telemetry data and how to orchestrate automated playbooks across complex enterprise systems.
Common Mistakes in Operations Engineering
Deploying machine learning models into production workflows introduces unique failure modes. Even highly experienced systems engineering teams frequently stumble when integrating AIOps in IT operations due to a few common, recurring pitfalls.
- Over-Alerting and Ignoring Noise Reduction: Configuring systems to send out alerts for every single anomaly detected by an algorithmic model burns out teams. The fix requires focusing configuration efforts strictly on high-severity, grouped incidents that present a clear threat to user-facing service levels.
- Treating the Platform as “Set and Forget”: Many teams treat machine learning software like a traditional appliance, assuming it will work perfectly out of the box without continuous guidance. The fix requires establishing routine feedback loops where operations engineers continuously audit, tune, and retrain underlying data models.
- Skipping Data Quality and Normalization: An analytical model is only as dependable as the information it processes. The fix requires prioritizing robust data hygiene, ensuring all telemetry inputs are structured, clean, and properly normalized before running advanced analysis.
- Automating Remediation Too Early Without Trust: Enabling full, self-healing automated scripts to modify live production systems before validating the accuracy of the underlying detection models can cause massive outages. The fix requires starting with an “advisor mode” where systems provide recommendations to human operators, manually validating accuracy before enabling full AIOps root cause analysis and automated playbooks.
- Lack of Cross-Team Buy-In: If your infrastructure engineers, database administrators, and application developers do not understand how an intelligent platform operates, they will bypass its recommendations. The fix requires involving all key engineering stakeholders early in the adoption process, clearly demonstrating how shared data science insights simplify troubleshooting.
AIOps for SRE: Enhancing Reliability Engineering
Site Reliability Engineering (SRE) relies heavily on quantitative metrics to balance system stability with software delivery velocity. Integrating AIOps for SRE provides the automated analytical capabilities required to maintain strict service level commitments across complex, high-scale application deployments.
The core value proposition for reliability engineers centers on optimizing key incident management metrics, specifically Mean Time to Detection (MTTD) and Mean Time to Resolution (MTTR). By continuously analyzing high-velocity data streams, machine learning models slash MTTD by identifying abnormal performance degradation long before a traditional static alert triggers.
Furthermore, the platform reduces MTTR by performing automated data correlation across disparate application layers. Instead of forcing an SRE on-call engineer to spend hours inspecting individual microservice logs, the system isolates the specific point of failure instantly. This automated triage ensures organizations protect their Service Level Objectives (SLOs) and maintain high application availability, protecting the business from costly service interruptions.
Seeing AIOps in Action
To understand how these concepts function in practice, let us walk through a detailed, step-by-step example of an incident unfolding within a highly distributed containerized infrastructure.
The Problem
At 2:15 AM, an enterprise financial application begins experiencing an intermittent slowdown. A downstream third-party payment gateway starts dropping connections, causing a payment microservice to stack up thread allocations. Within minutes, this thread exhaustion cascades upstream, causing the user-facing web front-end to slow down and drop twenty percent of transactions.
The Automated Response Workflow
- Detection: Rather than waiting for a legacy alert to fire when errors spike, the machine learning engine notes a subtle deviation in the payment microservice’s memory allocation and latency distribution compared to its typical 2:00 AM historical baseline.
- Correlation: As a flood of individual alert warnings begin emerging from the underlying container clusters, cloud load balancers, and application runtimes, the platform automatically intercepts them, grouping all 450 distinct alerts into a single, high-priority incident context.
- Root Cause Analysis: The system executes an automated AIOps root cause analysis. By tracing transaction pathways across network hops, it isolates the exact root cause: thread pool exhaustion in the payment service caused by unresponsiveness from the external payment gateway API.
- Remediation: The system acts on a pre-authorized engineering playbook. It updates the routing mesh to enable a circuit breaker on the failing payment gateway path, redirecting transactions to a backup payment processor while scaling up the payment microservice container count to clear backlogged threads.
The Measurable Result
Through this automated integration of AIOps in IT operations, the entire incident was identified, analyzed, and mitigated in just 4 minutes and 12 seconds. Under traditional manual operations engineering practices, pulling together various teams to identify this cross-boundary issue would easily take over 90 minutes of stressful troubleshooting, saving the financial institution thousands of dollars in lost transactions and protecting customer satisfaction.
How to Become an Operations Expert — Career Roadmap
Transitioning into an automated engineering role requires a structured approach to building skills. Professionals can follow this five-step career roadmap to navigate this evolving space successfully:
- Master Foundational Systems Engineering: Build a dependable baseline in core systems administration, networking, and cloud architecture to understand how modern computing platforms operate.
- Acquire Observability Expertise: Transition from simple uptime monitoring to deep system observability by learning how to aggregate logs, analyze application traces, and interpret complex telemetry patterns.
- Develop Automation Proficiency: Learn to write declarative infrastructure code, master scripting languages like Python or Go, and use orchestration tools like Ansible or Terraform to build self-healing playbooks.
- Complete Advanced Industry Education: Enroll in structured learning tracks designed to bridge data science concepts with real-world infrastructure systems. Actively pursue targeted AIOps Training, complete a specialized AIOps Course, and earn a well-recognized AIOps Certification to validate your operational skills.
- Specialize in Advanced Platform Engineering: Apply your skills within specialized disciplines like SRE, DevOps, or platform engineering, focusing on designing self-healing infrastructure pipelines for large enterprises.
Frequently Asked Questions
What is the difference between traditional monitoring and AIOps?
Traditional monitoring uses static thresholds to tell you when a system is already broken. Intelligent platforms use machine learning to look at real-time data streams, learn normal behavior patterns, and proactively flag anomalies before an outage occurs, while also automating noise reduction and root-cause analysis.
Do I need a degree in data science to work in this field?
No. Your role focuses on understanding how to integrate these tools, connect data pipelines, interpret automated insights, and build remediation workflows to optimize system reliability rather than building algorithms from scratch.
How long does it take to earn a professional AIOps Certification?
Most systems engineers with baseline IT experience can complete a structured training path and earn their AIOps Certification within six to twelve weeks of dedicated study.
What are the prerequisites for enrolling in an AIOps Course?
A foundational understanding of Linux administration, cloud computing basics, and standard IT monitoring practices is highly recommended. Familiarity with basic scripting concepts using Python or shell scripts will also help you get the most out of an AIOps Course.
Is there a specific entry-level credential for beginners?
Yes, professionals new to this space should pursue an AIOps Foundation Certification. This track focuses on mastering core concepts, understanding telemetry data types, learning noise reduction techniques, and understanding incident correlation before moving on to complex tool configurations.
How does machine learning reduce alert fatigue for on-call engineers?
The platform acts as an analytical filter. It automatically groups hundreds of related alerts stemming from a single infrastructure failure into a single incident ticket, removing background noise so teams can focus on a single, clear issue.
Can these tools run inside hybrid and on-premises data centers?
Yes. Modern platforms use flexible architectures that seamlessly unify data across legacy on-premises servers, private VMware environments, and modern multi-cloud deployments into a single operational interface.
Why Get an AIOps Certification?
As companies invest heavily in intelligent IT platforms, proving you know how to operate these complex systems is essential for career advancement. Earning an official AIOps Certification provides a clear advantage in a highly competitive technology job market.
First, it establishes immediate professional credibility. Having an AIOps Foundation Certification on your resume proves to engineering managers that you possess a verified grasp of automated operations, data orchestration, and algorithmic triage, setting you apart from candidates who only understand traditional monitoring.
Second, a certification path provides a structured framework for learning. Instead of trying to patch together skills from random online tutorials, a certified program ensures you master all foundational building blocks sequentially—from data ingestion and noise filtering to advanced root-cause analysis and automated playbooks.
Finally, this specialized knowledge provides significant leverage for salary negotiations and promotions. Organizations are eager to hire engineers who can cut down incident resolution times and reduce operational waste. Gaining these validated skills positions you for high-demand roles in Site Reliability Engineering, cloud architecture, and platform operations.
Where to Learn AIOps
Building a successful career in intelligent operations requires a comprehensive educational partner that balances core theory with practical experience. AiOpsSchool provides a robust selection of learning resources tailored specifically to meet modern enterprise demands:
- AIOps Training: Immersive, hands-on instructional programs designed to take you from foundational concepts to advanced production deployments under the guidance of industry experts.
- AIOps Course: Deep-dive modular learning paths covering critical subjects including telemetry data pipelines, event correlation tuning, and predictive resource forecasting.
- AIOps Certification: Globally recognized professional validation programs that verify your technical expertise to enterprise employers and accelerate your career advancement.
- AIOps Tutorial: Step-by-step practical guides and lab exercises designed to give you direct experience configuring leading enterprise observability and automation platforms.
Final Thoughts
The window for managing enterprise scale through traditional, manual operations methods is rapidly closing. As modern infrastructures grow more distributed and complex, organizations must embrace automation to keep pace. For technology professionals, this operational shift represents a major career opportunity to transition away from stressful, reactive firefighting and into high-value engineering roles.
Investing in your professional growth through structured AIOps Training is the most effective way to stay ahead of this industry evolution. By earning an official AIOps Certification, you gain the specialized skills needed to architect resilient, self-healing systems and lead modern engineering teams. Take control of your career path today by exploring the comprehensive training programs and certifications available at AiOpsSchool.com.